Abstract
Scaling up robot learning is hindered by the scarcity of robotic demonstrations, whereas human videos offer a vast, untapped source of interaction data. However, bridging the embodiment gap between human hands and robot arms remains a critical challenge. Existing cross-embodiment transfer strategies typically rely on visual editing, but they often introduce visual artifacts due to intrinsic discrepancies in visual appearance and 3D geometry.
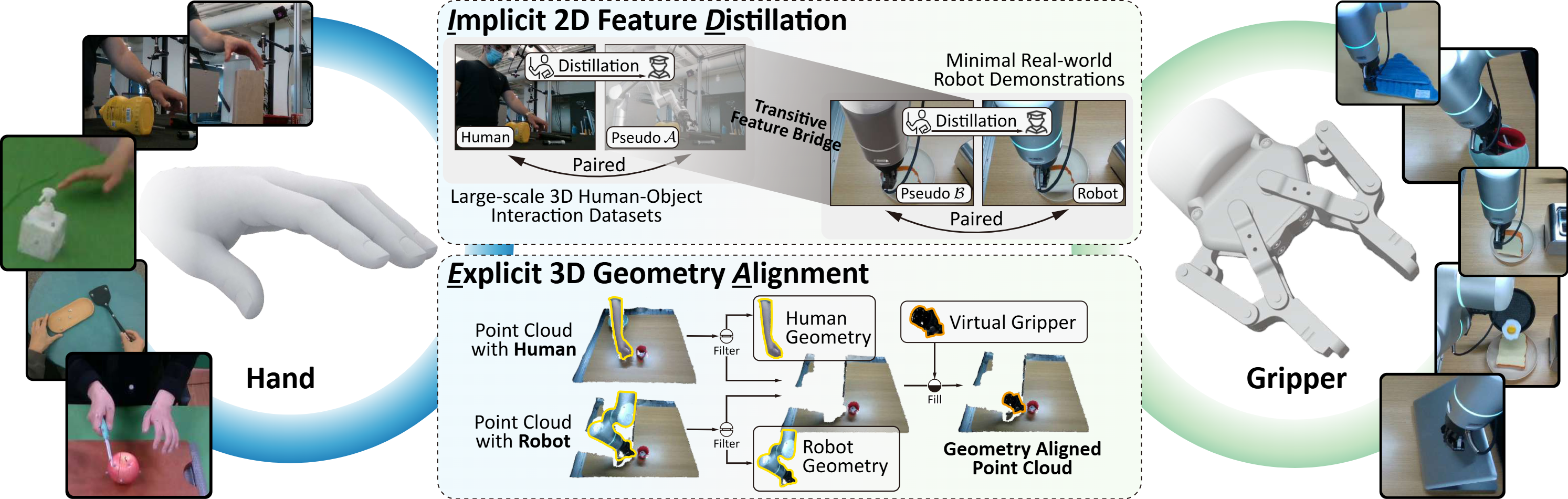
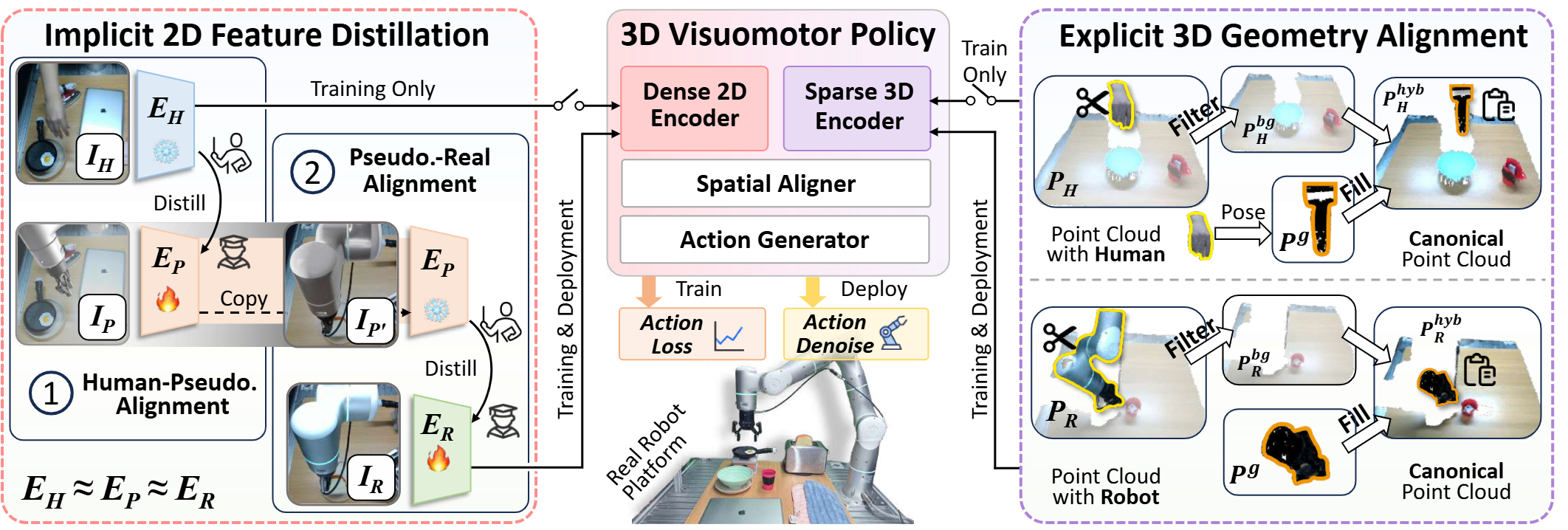
To address these limitations, we introduce LIDEA (Implicit Distillation and Explicit Geometric Alignment), a novel framework that enables direct policy learning from human videos. In the 2D visual domain, LIDEA employs a dual-stage transitive distillation pipeline that aligns human and robot representations in a shared latent space. In the 3D geometric domain, we propose an embodiment-agnostic alignment strategy that explicitly decouples embodiment from interaction geometry, ensuring consistent 3D-aware perception.
Extensive experiments empirically validate LIDEA through two complementary protocols evaluating data efficiency and cross-embodiment robustness. Results show that human data substitutes up to 80% of costly robot demonstrations, and the framework successfully transfers unseen patterns from human videos for out-of-distribution generalization. Our code and dataset will be made public.